Machine learning
Data Processing
This study devises a sentimental analyzer to identify Tweets test sentiment, whether positive or not. Because the input of machine learning model should be numeric, in the first place we need to transform the sentiment type (y-variable) and tweet text (x_variable) into numeric types. We set ‘negative’ to 0, neutural to ‘1’ while positive to ‘5’. Then for tweet text, CountVectorizer is applied to transform the text to array format.
tweets_df['senti_label']=tweets_df.Sentiment.apply(lambda x: 0 if 'Negative'in x else 1 if 'Netural' else 5)
y=tweets_df['senti_label']
from sklearn.feature_extraction.text import CountVectorizer
cv=CountVectorizer(max_features=3000)
X_fin=cv.fit_transform(cleaned_data).toarray()
X_train,X_test,y_train,y_test=train_test_split(X_fin,y,test_size=0.3, random_state=123)
Compare with different models
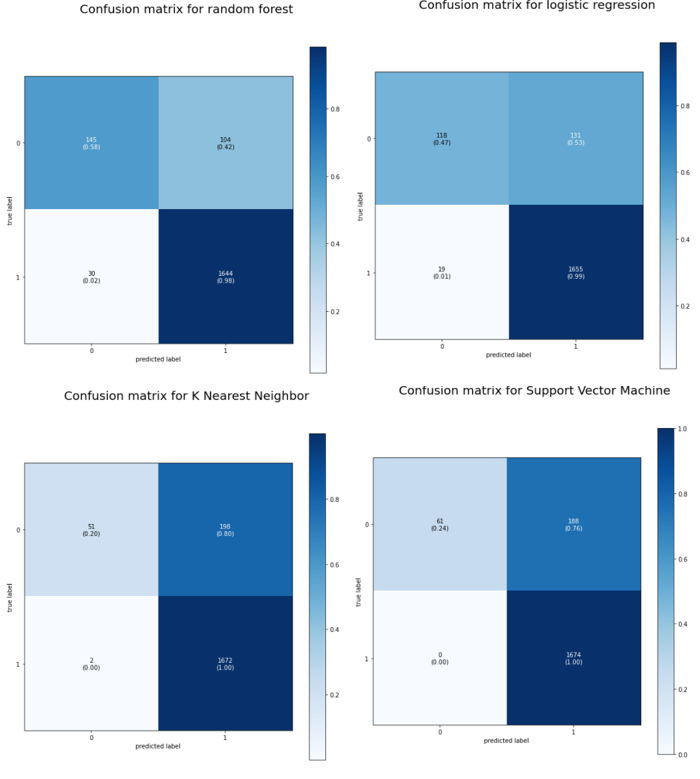
Several models, including logistic regression, K Nearest Neighbor, SVM, random forest, were built, trained and compared. The one with the highest accuracy, recognized as the randomforest, will be chosen as the most optimal one.
Random forest
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=250, random_state=0)
rf_clf.fit(X_train, y_train)
y_pred1 = rf_clf.predict(X_test)
print("Results for Random forest")
print("Accuracy:",accuracy_score(y_test,y_pred1))
Results for Random forest
Accuracy: 0.9303172126885075
Logistic Regression
from sklearn.linear_model import LogisticRegression
log_model = LogisticRegression()
log_model = log_model.fit(X=X_train, y=y_train)
y_pred2 = log_model.predict(X_test)
Results for Logistic Regression
Accuracy: 0.921996879875195
Support Vector Machine
svcl = svm.SVC()
svcl.fit(ctmTr, y_train)
svcl_score = svcl.score(X_test_dtm, y_test)
y_pred3 = svcl.predict(X_test_dtm)
Results for Support Vector Machine
Accuracy: 0.9022360894435777
K Nearest Neighbor
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(ctmTr, y_train)
knn_score = knn.score(X_test_dtm, y_test)
y_pred4 = knn.predict(X_test_dtm)
Results for K Nearest Neighbor
Accuracy: 0.8959958398335933
picture for confusion matrix.
Validation
To further evaluate its performance, a random sentence that contains obvious positive sentiment words is chosen, and the results shows that its positive probability is 86.88%, while 13.11% for negative. We believe the accuracy of model can be further enhanced in the future.
rf_clf.fit(x1,y1)
test_sentence = vectorizer.transform(['I love covidvaccine!'])
rf_clf.predict_proba(test_sentence)
array([[0.13118602, 0.86881398]])
- See the code of Machine Learning.