Data collection and processing
Data collection
To begin with we will be using twitter’s developer app to extract data from 1st January 2021 to 14th December 2021 by filtering the location with USA or United States. We research for the most used hashtags in social media pertaining to COVID 19 vaccine and we narrow it to #covidvaccine #Covid19vaccine, and to further fine tune and be precise with the analysis we also extract tweets with #pfizervaccine and #Modernavaccine as these are the two trending vaccine providers in the US.
- See the code of Pulling recent data and the Pulling historical data.
Data Preprocessing
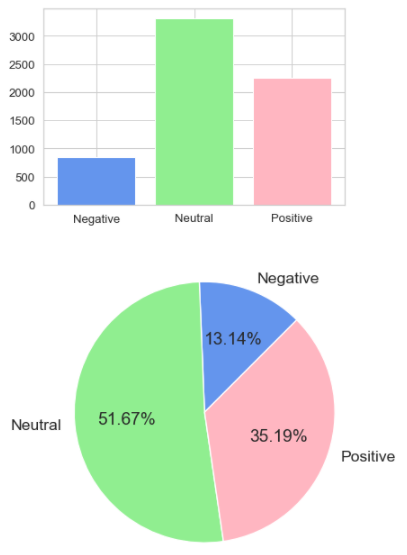
Once we are done extracting tweets we clean the data by removing punctuations, URLs amongst others, further we homogenise the tweets, location and data for easy handling and consistency, converting all tweets to lowercase, etc. Initially we run the sentimental and emotional analysis on all the 50 states through Tweepy and TextBlob to calculate the polarity and subjectivity, then label the sentiment score depending on the positively, negatively and neutrality of the tweets.
- See the code of Data preprocessing.